

400-123-4567
站内公告:
2024-03-11 12:58:33
每次迭代都需要把所有样本都送入,这样的好处是每次迭代都顾及了全部的样本,做的是全局最优化。
缺点:要放入全部样本,速度慢
针对梯度下降算法训练速度过慢的缺点,随机梯度下降是从样本中随机抽出一组,训练后按梯度更新一次,然后再抽取一组,再更新一次,在样本量极其大的情况下,可能不用训练完所有的样本就可以获得一个损失值在可接受范围之内的模型了。
torch中的api为:
缺点:当我们样本中存在噪声时,随机输入的样本可能会影响结果,梯度的更新不一定是全局最优化的方向,只是样本数量减少而计算的比较快。
找一波数据计算梯度,使用均值更新参数。
缺点:
主要是基于梯度的移动指数加权平均,对网络的梯度进行平滑处理,让梯度的摆动幅度变小。下图中的0.8和0.2是例子,并不固定。

AdaGrad算法是将每一个参数的每一次迭代的梯度取平方累加后再开方,用全局学习率除以这个数,作为学习率的动态更新,从而达到自适应学习率的效果。
下图中是w是当前的梯度。
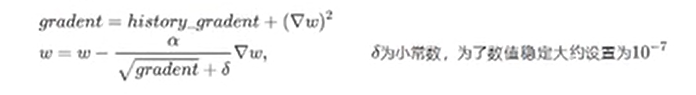
动量法中虽然初步解决了优化中摆动幅度打的问题,为了进一步优化损失函数在更新中存在摆动幅度过大的问题,并且进一步加快函数的收敛速度,RMSProp算法对参数的梯度使用了平方加权平均数。是对学习率进行加权。
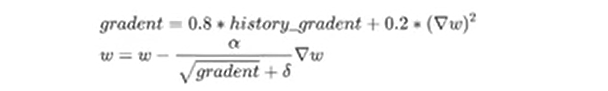
Adam(Adaptive Moment Estimation)算法是将Momentum算法和RMSProp算法结合起来使用的一种算法,能够达到防止梯度的振幅过大,同时还能够增加开放收敛速度。
同时对学习率和梯度进行限制,保证了梯度的振幅不会过大。

torch中的api为:
其中BGD、SGD和MBGD是机器学习方法,后三种为深度学习方法。
动量法是对梯度进行的限制,AdaGrad和RMSProp是对学习率进行的限制,Adam是对学习率和梯度都进行了限制。




